精品为您呈现,快乐和您分享!
收藏本站
 安卓修改大师v10.36
安卓修改大师v10.36
 3d one教育版v2023.03官方版
3d one教育版v2023.03官方版
 猿编程客户端v3.49.1官方版
猿编程客户端v3.49.1官方版
 Visual Studio Code(微软代码编辑器)v1.82.2.0官方版
Visual Studio Code(微软代码编辑器)v1.82.2.0官方版
 核桃编程v2.1.123.0官方版
核桃编程v2.1.123.0官方版
 G2(可视化引擎)v5.0.12官方版
G2(可视化引擎)v5.0.12官方版
 一鹤快手(AAuto Studio)v35.69.2免费版
一鹤快手(AAuto Studio)v35.69.2免费版
 快手(AAuto Quicker)v35.69.2官方版
快手(AAuto Quicker)v35.69.2官方版
 aardio(桌面软件开发工具)v35.69.2官方版
aardio(桌面软件开发工具)v35.69.2官方版
 Git客户端v2.41.0.1官方版
Git客户端v2.41.0.1官方版
应用简介
Tesseractocr 是一个图像识别类库,最初由HP 开发,后来成为Opensource。据说其图像识别能力一度排名第三。提供给您的版本是4.0.0 for windows。
tesseract ocr是最初由HP开发的图像识别类库,后来成为开源的。据说其图像识别能力一度排名第三。提供给您的版本是4.0.0 for windows。
指示
下载后,安装它。默认情况下,安装程序会为你配置系统环境变量指向安装目录(然后你可以通过DOS界面在任意目录下运行tesseract)。安装完成后目录如下:
附录:
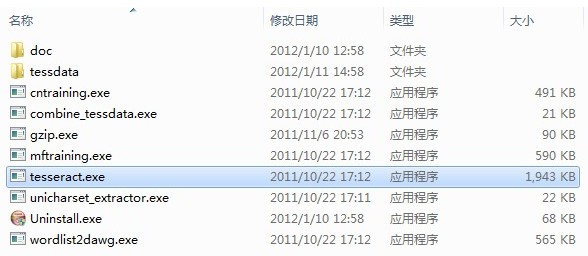
tessdata目录存储语言字体文件和与可以在命令行界面中使用的参数相对应的文件。该安装程序默认包含英文字体。
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:
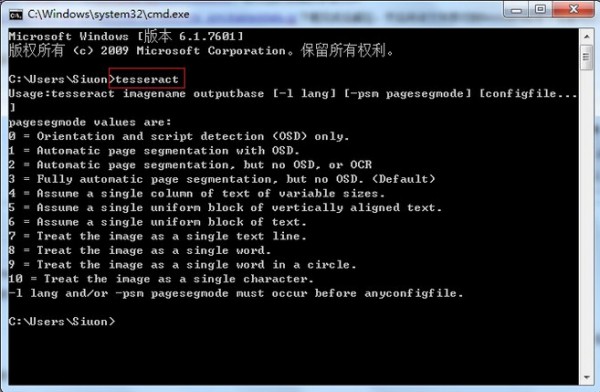
如果出现以上输出,则说明安装正常。
我已准备好验证码
放到D盘根目录下,如上图:
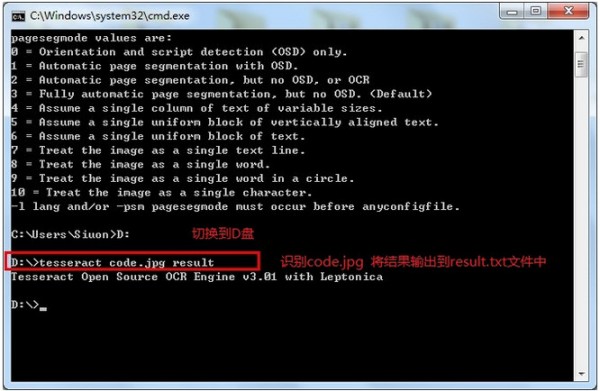
结果是:
附录:
用法:tesseract 图像名称输出库[-l lang] [-psm Pagesegmode] [configfile.]
pagesegmode 值为:
0=仅方向和脚本检测(OSD)。
1=使用OSD 自动页面分段。
2=自动页面分段,但没有OSD 或OCR
3=全自动页面分割,但无OSD。 (默认)
4=假设单列文本大小可变。
5=假设有一个统一的垂直对齐文本块。
6=假设一个统一的文本块。
7=将图像视为单个文本行。
8=将图像视为单个单词。
9=将图像视为圆圈中的单个单词。
10=将图像视为单个字符。
-l lang 和/或-psm Pagesegmode 必须出现在任何配置文件之前。
tesseract 图像名称输出库[-l lang] [-psm Pagesegmode] [配置文件.]
tesseract 图片名输出文件名-l 字体文件-psm Pagesegmode 配置文件
例如:
tesseract code.jpg 结果-l chi_sim -psm 7 nobatch
-l chi_sim 表示使用简体中文字体库(需要下载中文字体文件,解压后存放在tessdata目录下,字体文件扩展名为.raineddata,简体中文字体文件名为:chi_sim.traineddata )
-psm 7 告诉tesseract code.jpg 图像是一行文本。该参数可以降低识别错误率。默认值为3
configfile参数值是tessdata\configs和tessdata\tessconfigs目录中的文件名。
热门攻略
热门资讯